Day 14 : 資料驗證 TensorFlow Data Validation (TFDV)
tags: MLOps
 第 13 屆鐵人賽鍊成
第 13 屆鐵人賽鍊成資料是機械學習重要的核心,用於生產的機械學習必須考量大量且快速的資料情境,使用自動化、可擴展的資料分析、驗證以及監控方法相當重要。 TensorFlow Data Validation (TFDV) 為 Google 開源的資料驗證模組,可做為用於生產的機械學習組件之一,也可以融入您在筆記本的研究流程。
什麼是 TensorFlow Data Validation (TFDV)

圖片來源 TFX
- Tensor Flow Data Validation (TFDV) 是個由 Google 開源的模組,平時可以作為 TensorFlow Extended (TFX) 的一個組件,也可以獨立運用。
- TFDV 可幫助開發人員大規模理解、驗證和監控 ML 數據,Google 每天都使用這項技術來分析和驗證數 PB 的數據(如: Gmail )。能及早捕獲數據錯誤,幫助 TFX 用戶保持其 ML 管道的健康。
- TFDV 可以在 Notebook 環境中執行,方便銜接開發及部署的流程。說到流程,整個 TFX 大架構採用 Apache Beam 的數據處理框架, 如您不熟可以先當目前 Google 採用,類似 Hadoop 具有可水平擴展的框架理解。
- TFDV 結合開源的 Facets ,是可以幫助理解和分析機器學習數據集的開源可視化工具,在 Google AI Blog 中展示了透過 Facets 視覺化抓出 CIFAR-10 資料集中一個錯誤分為貓咪的青蛙的圖片。
- TFDV 容許兩個資料及之間的分布對照,例如訓練資料與測試資料,迅速抓出資料飄移與偏斜情形,而 TFDV 更進一步可以做到修正與納入新特徵,以及整合在筆記本及 TFX 之中。
- 本篇先聚焦 TFDV ,大架構 TFX 後續再用專文介紹。
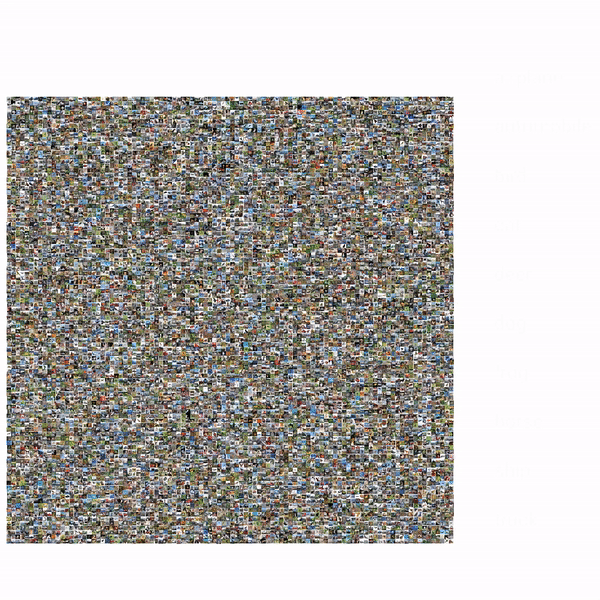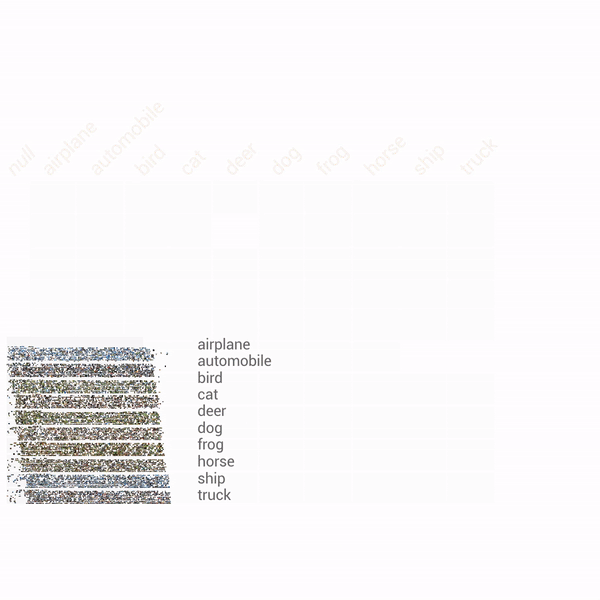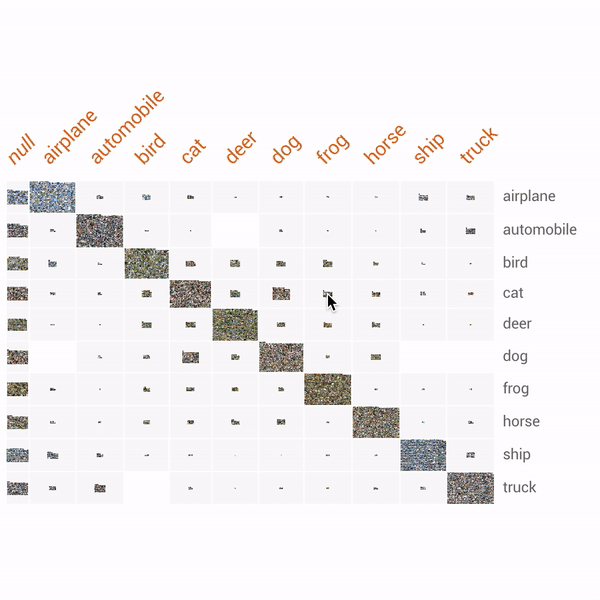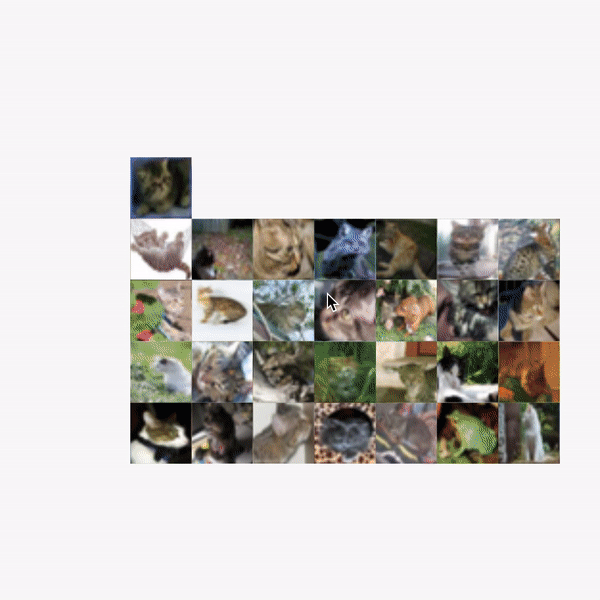
TFDV 可以做什麼
- TFDV 可以分析訓練和服務數據,並可在 Notebook 使用,用途包含:
- 描述性統計分析、探索式資料分析 EDA。
- 推斷 Schema 。
- 檢測數據異常。
- 修正數據異常。
從 TFDV API 認識功能
功能介紹引用 TFDV官方教學文件,也提供 Colab 實作範例  可直接執行,您可以相互參照。
可直接執行,您可以相互參照。
建立環境
引入
tensorflow-data-validation模組。!pip install tensorflow-data-validation如您使用 Colab ,有更動TensorFlow或安裝TFX,請依指示安裝完重新啟動(Runtime > Restart runtime)。
TFDV 吃什麼
輸入為
csv、DataFrame與TF Record,變成可用統計數據。tfdv.generate_statistics_from_csv
tfdv.generate_statistics_from_dataframe
tfdv.generate_statistics_from_tfrecord
統計訊息視覺化
直觀呈現從數據生成的統計信息。
紅字表示 TFDV 覺得異常供您判斷,下圖為芝加哥計程車資料集裡小費為 0 的有 68% ,相當直觀。
tfdv.visualize_statistics()
推斷及顯示資料的 Schema
推斷並建議初始 Schema,以及顯示。
TFDV 自行推斷 Schema,其中 Domain 的各文字屬性也表列呈現。
tfdv.infer_schema
tfdv.display_schema

資料驗證
將新舊不同版本統計與Schema對照來檢測異常。
statisticsserving_stats可檢測訓練服務偏差,previous_statistics可檢測偏移。tfdv.validate_statistics以官方範本舉例2版本統計對照寫法與輸出
tfdv.visualize_statistics(
lhs_statistics=eval_stats,
rhs_statistics=train_stats,
lhs_name='EVAL_DATASET',
rhs_name='TRAIN_DATASET'
)
- 對照訓練與評估資料集,有些分布不一致,會不會影響模型結果?
顯示異常
將徵測到的異常呈現及說明,輕鬆寫意。
tfdv.display_anomalies# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
在 Google TFDV 說明簡報中,您可以看到左方為 資料與 Schema,右方紅字為對照 Schema 的差異。

- 圖片來源: Google TFDV 說明簡報。
修復異常
您可以依您的 Domain Knowledge 決定對異常採取的措施。如果異常表明數據錯誤,則應修復底層數據。否則,您可以更新納入 Schema 以納入。
TFDV 的異常處理參數請見官方文件,異常可能歸類於資料型態的問題、未知 Domain 出現、超過數值邊界值範圍。
如果已經發現異常 Domain 處理,官方範例可以參考,其一是放寬異常特徵的看法,其二將該特徵納入Domain。
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')另外您也可以透過Pandas操作DataFrame的方式整理資料,像是
df.dropna()、df=df[df['some_column']<100]進行篩選與過濾。Pandas 快速指引可以參閱10分鐘的Pandas入門-繁中版。再次檢視異常處理情形:
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
- 修正過關。
監測 Skew
TFDV 可以檢測 Schema 偏斜、特徵偏斜和分佈偏斜。
# 對 payment_type 特徵加入 skew 比對
payment_type = tfdv.get_feature(
schema,
'payment_type'
)
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# 對 company 特徵增加 drift 比對
company=tfdv.get_feature(
schema,
'company'
)
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(
train_stats,
schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats
)
tfdv.display_anomalies(skew_anomalies)
儲存 Schema
設定好儲存檔案位置
schema_file,將schema存為*.pbtxt,完整程式參見官方範例。tfdv.write_schema_text(schema, schema_file)
用於生產流程中的 TFDV
在探索式資料分析 EDA 之中, TFDV 可以檢測並輸出調整後的 Schema。在生產流程之中,可以用Schema與生產中的資料統計資訊進行驗證,對比與檢測可能出現的 Data Drift 與 Skew ,並據以修正。

您可以完成持續跨日的追蹤數據,例如有了第1日 schema 與統計資訊,可進行與 t 日的比對。。

小結
- TFDV 開源可獨立作為模組運用,您可以輸入 CSV,產生 Schema 用來驗證後續的資料流有無異常,修正異常,建立檢測門檻。視覺化的介面也可以勝任 EDA 用途,這麼香不應該只有我知道。
- TFX 是端對端完整的資料工作流程,TFDV 可以融入其中,也基於中文文件缺乏故會多些篇幅介紹。
